...increasingly seems to be impossible. Democrats dislike Republicans; Republicans dislike Democrats; even within liberal enclaves, very liberal campus activists dislike slightly less liberal campus activists. More than one of my friends has told me that, if they could work on any problem, they would want to stitch closed these schisms in our society.
Recently I had two experiences that renewed my faith that this was possible. I started contentious discussions with two very different groups:
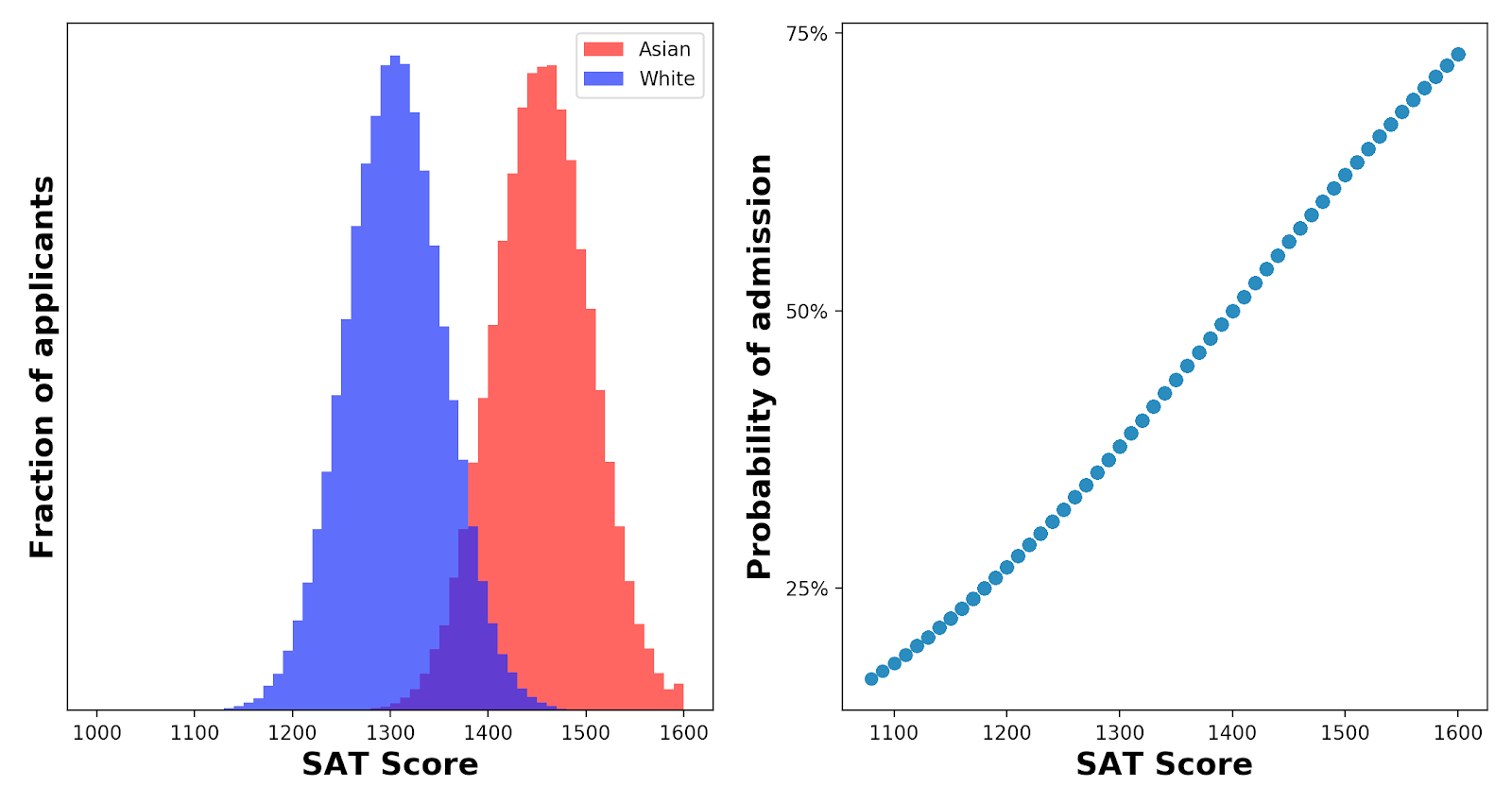
1. The Redditors: A bunch of Reddit fans of a popular blogger who, in my view, can be biased against feminists. He had written a piece arguing that the focus on powerful men’s sexual assaults was “a hit job” on men. I wrote a rebuttal, decided I was feeling confrontational, and posted it where all his Reddit fans would see it.
2. The AlterConfers: The attendees of AlterConf 2017, a conference that “provides safe opportunities for marginalized people and those who support them in the tech and gaming industries”. I had been invited to speak about ethical dilemmas in computer science, and decided I would begin my talk by talking about criminal justice sentencing algorithms. I was going to argue that algorithms that created large racial disparities were not necessarily unfair.
These groups, as you can imagine, followed profoundly different norms. When I arrived at AlterConf, I was asked for my preferred pronouns (she/her) and told that the bathrooms had been “liberated from the gender binary”; when I posted on Reddit, a commenter immediately assumed I was male. At AlterConf I was asked whether my talk had any trigger warnings and handed red, yellow and green cards to indicate whether I was comfortable talking to other people; on Reddit, I found a similarly careful means of communication that relied on a totally different vocabulary -- “motte and bailey”; “toxoplasma”; “infinite regress”; “Taleb’s notion of time probability”; “eudaimonia”, “metis”, and “episteme”; "Foucaultian nihilism” and “biopower”.
I doubt the two groups would get along that well. At AlterConf, multiple speakers attributed social problems to cis white men; on Reddit, multiple commenters criticized feminists instead. At AlterConf, speakers discussed how to stop racial discrimination; on Reddit, commenters focused instead on discrimination against men. (Like African-Americans, they argued, men were discriminated against by the criminal justice system.)
Nor was I arguing positions that either group was particularly sympathetic to. Reddit isn’t known for loving feminist positions; similarly, arguing that the criminal justice system isn’t as racist as it appears to be isn’t a popular stance in activist circles. I was genuinely nervous before engaging with each group.
But in fact both interactions went remarkably well: no one got mad, I learned from both groups, and they learned from me. On Reddit, commenters pointed me to a long line of papers showing discrimination against men in criminal justice, which I wrote some code to check out -- more on this some other time. They also asked me for recommendations of other blogs to read, machine learning resources, why feminists acted the way they did, and why I had worked at 23andMe, so information flow went both ways. At AlterConf, I heard ideas for making tech conferences safer and more inclusive (take note, NIPS); making code reviews more pleasant; and finding books with more diverse protagonists, among many others. Conversely, many people came up to me after my talk to ask about tradeoffs in algorithmic fairness.
Why was this communication peaceful and productive? Here are some thoughts.
1. Both communities established strong norms of respectful discourse. These norms are wildly different, of course -- on Reddit, you get a lot of rationalist jargon, and at AlterConf, you get a lot of activist jargon. But they share a common goal: to allow everyone to participate in a free discussion without getting insulted or upset. And while I don't agree with all the ways these communities achieve this goal -- sounding super-rational can sometimes just conceal silly arguments or be pretentious, for example, and I think trigger warnings, while useful in some cases, are used over-broadly -- it helps to just establish a common intention that we're all trying to get along.
Sometimes, the norms are very effective at preserving civil discourse. For example, the one Reddit commenter who was overtly disrespectful, questioning how I had managed to earn my professional bona fides when I wrote like a high schooler, was swiftly downvoted and told they were violating the rules of the forum; their comment was then deleted. One norm I particularly like is charity, a term I heard mentioned frequently on Reddit. As I understand it, charity means "assume good intent and respond to the strongest version of the opponent's argument". I love this ideal, although I don't always achieve it [1].
2. I showed willingness to learn. On Reddit, I began my rebuttal with a long paragraph listing all the things I had learned from the original blog post, and when commenters disagreed with me, I asked them for references. At AlterConf, I started by saying I was grateful to be invited to speak because I thought the wider CS community could take a lot of useful lessons from AlterConf. I also told them that I was about to give a short talk on a controversial topic to a new community, which was always risky, so I was nervous and if they disagreed they should come talk to me because I liked talking to people who disagreed with me.
This willingness to learn was not an act: it helps me to approach new communities anthropologically, with openness, curiosity, and some degree of detachment, and view things I don't agree with as interesting and well-intentioned rather than stupid and malignant. Of course, I don’t always manage to do this.
3. We came from similar tribes. On Reddit, I could credibly claim to be a rationalist math nerd, and the fact that I was in the Stanford CS program was a good thing; had I picked a fight on Breitbart, I suspect I’d have been cast as a liberal elite. Similarly, at AlterConf, I started by saying I studied police discrimination to try to establish that my heart was in the right place.
I'm not sure any of these strategies would allow you to bridge a wider schism and engage with, say, Fox News commenters. But maybe we don't need to do that yet. Even within the Democratic party, there are schisms that if bridged would help us win elections. And, more broadly, if you start by reaching out to the most distant people who will listen to you, perhaps little by little that frontier grows more distant.
Notes:
[1] In my experience, the activist community isn’t always charitable either; I dislike how people are sometimes demonized when their intent is benign, as I’ve discussed before. But at AlterConf everyone was nice to me.