Content warning: this post discusses sexual assault in some detail.
A few weeks ago I created a statistical model which implied that someone who has been accused of sexual assault by multiple people is much less likely to be innocent than someone who has been accused of assault once. This ended up on the front page of Hacker News, which Wikipedia describes as a “social news website that caters to programmers and entrepreneurs”, and got as many views in two hours as this blog usually gets in two months. (Granted, that’s not really that much traffic, but we math nerds take what social interaction we can get.)
A few weeks ago I created a statistical model which implied that someone who has been accused of sexual assault by multiple people is much less likely to be innocent than someone who has been accused of assault once. This ended up on the front page of Hacker News, which Wikipedia describes as a “social news website that caters to programmers and entrepreneurs”, and got as many views in two hours as this blog usually gets in two months. (Granted, that’s not really that much traffic, but we math nerds take what social interaction we can get.)
While many of the comments were critical, almost all of them were civil, thoughtful, and free from the kind of trolling that women worry about when discussing controversial gender issues. All this was tremendously welcome and we need more of it on the internet, so I thought I’d take the time to respond to the most interesting criticisms.
To briefly recap (skip to the next paragraph if you remember all this) the model computes the probability that someone who has been accused of sexual assault by k people has never actually committed assault. The model assumes that there are serial predators, who have a high probability of assaulting people, and non-serial predators, who have a low probability of assaulting people. If someone has been assaulted, they accuse the other person of assault with probability pag; if they have not, they accuse with lower probability pai. You can play with the model here (move the sliders).
As I note in the post, the model is a simplification of the real world, as all models are. That said, it is possible to build a model which is too simple. For example, after Thomas Duncan’s nurse became infected with Ebola, it would’ve been irresponsible to say, “Assuming the current rate of weekly doubling of the Ebola epidemic in the United States continues, we expect every US citizen to be infected 28 weeks from now.” So I will discuss three assumptions the model makes and you can judge their validity and usefulness for yourself. Overall my view is that, while the model simplifies out of necessity, its basic conclusions probably hold even under more complicated assumptions. But I also see why there is room for disagreement because of the uncertainty about basic facts about assault, and trying to build a model has definitely reinforced my belief that we need better data. There also are clear tradeoffs between reducing the number of assaults and not punishing innocent people; your background and life experiences differ from mine, so you may worry more about victims of assault and less about the wrongfully accused, or vice versa.
- Objection 1: the model assumes that each accuser comes forward independently, but in fact each accuser may be influenced by previous accusers. This was the main concern people on Hacker News raised [1], and I think it is definitely important in high-profile cases like Bill Cosby’s, where accusers may well know about and be influenced by previous accusations. But I do not think cases like Cosby’s are the most representative or important to focus on, because the vast majority of accused and actual rapists are not famous. In these more representative cases, I do not think we should worry too much about accusers influencing each other for several reasons.
- In my post I discuss a tool which allows accusers to file accusations with a third party who will keep the accusations confidential unless multiple accusations are levied at the same person. If this tool were used, it seems quite likely that accusations would be essentially independent because they would be kept secret. (I guess it is possible that accusers might collude and all submit accusations together, but this John Tucker Must Die scenario stretches the bounds of plausibility.)
- Even if this tool is not used, accusers have to know about previous accusations to be influenced. This is by no means certain: how many people do you know who are currently being accused of assault? How often do you compare notes with someone who has had a sexual encounter with the same person?
- Even if accusers are aware of previous accusations, either i) they were actually assaulted, in which case it’s a good thing if they’re more likely to come forward or ii) they were not actually assaulted, in which case it’s a little unclear why they’re now more likely to come forward. The thought process might go something like, “Well, I’m not sure exactly what happened...I thought it was consensual at the time, but if they attacked other people, I guess they attacked me too.” This seems a bit unlikely to me, but feel free to suggest more plausible reasoning.
- Even if you disagree with all of the above speculations about probabilities, I built you another model that allows you to adjust them (you might have to zoom out to see all the sliders) and account for accusers who influence each other. I describe the mathematical details here [2]. Even if accusers can influence each other quite strongly, this model yields the same conclusion as before: someone accused of sexual assault multiple times is much less likely to be innocent. For example, I still see the same effect if I make an accuser ten times more likely to accuse an innocent person of assault if they learn they’ve been previously accused.
2. Objection 2: the model assumes that everyone is equally likely to be accused of assault. Several people pointed out that there are factors that influence how likely a person is to be accused of assault besides whether they actually assaulted someone. To take one example, someone who has sex with their partner of ten years may be less likely to be accused than someone who has sex with a person they met for the first time at a frat party, even if both encounters are consensual. More generally, we can imagine two groups of people, A and B, who have different sorts of sexual encounters, and thus different probabilities of being innocent:
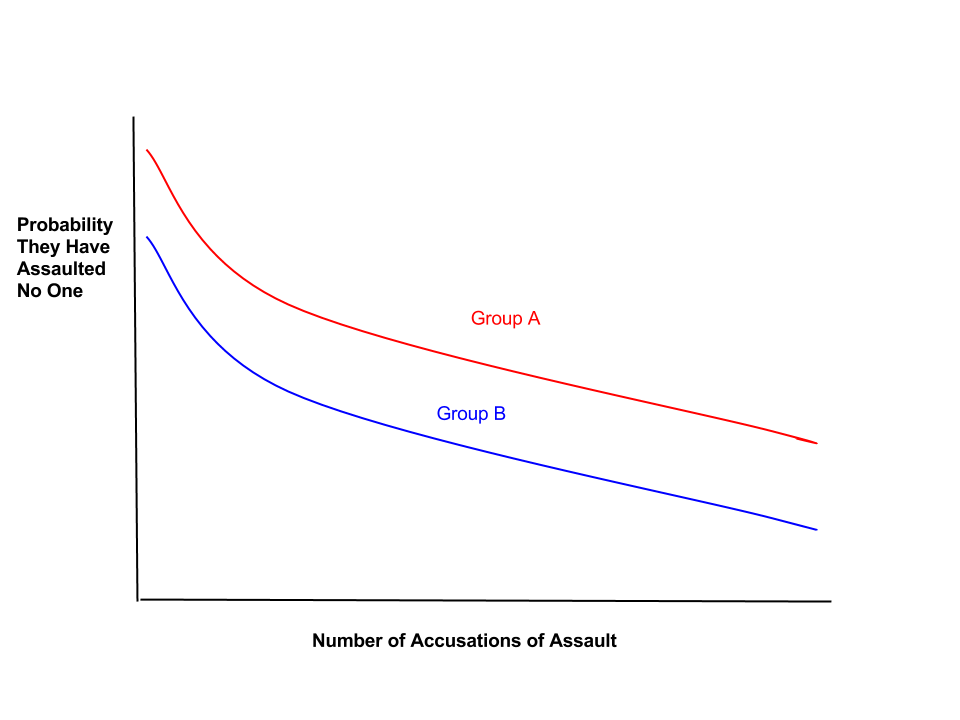
I think this only alters our basic conclusion, though, if we think of a group who is a) reasonably large and b) a lot more likely to be accused of assault even when they are innocent. (Merely identifying group differences is not enough: you would have to identify a group for whom we can set the parameters of the original model such that the innocence curve no longer plunges sharply.) None of the people I spoke to about this advanced plausible candidates for such a group, but let me know if you have thoughts.
3. Objection 3: the model computes the probability that the accused is guilty of at least one assault, but that is not the probability we are interested in. In no court would a judge say, “Well, I don’t know which of these six alleged assaults the accused is guilty of, but there’s a very high probability he’s guilty of at least one, so I’m throwing him in jail.”
Still, when we’re not throwing someone in jail, we often do care about the probability the model computes. Maybe I’m in charge of student housing, someone’s been accused of assault by two of their dorm mates, and I’m trying to decide whether to move them to another house (or out of housing altogether). We frequently apply statistical reasoning that isn’t allowed in a courtroom.
Also, it turns out we can use a similar model to compute the probability that someone is guilty in a particular case (rather than in any case) given that they have k previous accusations of sexual assault, and it produces similar curves [3].
If you’ve made it this far, especially if you disagreed with me at the outset, thanks so much for reading, because I wrote this mainly for you. I imagine we still have disagreements and would welcome your comments below or via email.
Notes:
[1] Some made comparisons to witchcraft trials, where a “mob mentality” takes hold and many people accuse one person of witchcraft. I will say, first, that I think witch trials are so different as to make this comparison pretty useless. A large number of people are truly assaulted; no one is a true victim of witchcraft. I do not believe there are mobs of potential assault accusers who, having all had sex with the same person, are suddenly all possessed by groupthink and decide that their sexual encounters constituted assault.
[2] The model assumes that if someone’s been previously accused of assault, a potential accuser knows about it with probability pk; if they know about the previous accusations, they accuse with probability pag1 if the person assaulted them and pai1 if the person did not; if the potential accuser does not know about the previous accusations, they accuse with probability pag0 if the person assaulted them and pai0 if the person did not. As pk goes to zero -- no accuser knows about the others -- we recover the old model, where every accuser acts independently. On the other hand, if we increase pk and pai1 to 1 -- accusers are certain to know about the first accusation, and certain to accuse if they know about it -- every accusation after the first becomes uninformative, as we would expect. We see the same effect as in the old model even for quite high settings of pk and pai1 -- which can’t be all that high by simple virtue of the fact that very few people are accused of assault -- someone who is accused multiple times is much less likely to be innocent.
[3] The lawyers I discussed this with are still uncomfortable with this kind of reasoning, where past accusations can influence present guilt. My general sense is that the legal system disallows a lot of reasoning that statisticians deem kosher -- which is probably, given the weight we place on not convicting the innocent, a good thing.
Very thoughtful and well-constructed post, Emma!
ReplyDeleteThanks, Aaron! I miss you.
Delete1. The model does not need to be limited to sexual assault; it applies to any behavior, or at least to any "bad" behavior. Thinking about less dramatic behaviors may help explain some of the objections, such as the potential for "herd mentality", or making similar accusations as a form of solidarity/distancing.
ReplyDelete2. The assumption of serial predators being responsible for most assaults is a strong assumption, and there is some evidence against it.
3. I'm not sure it is reasonable to assume that false allegations are always from the pool of people the accused actually had sex with. In other words, the question won't always be "how likely is someone to decide it wasn't consensual after all"; sometimes the question might be "if someone is making a false accusation, how likely are they to make it about person Y in particular?" (Of course, too many sliders for different categories of false starts to get into the degrees of freedom problem.)
4. It isn't (just) that lawyers are uncomfortable with the reasoning; it is that court procedures make it (theoretically, in general) irrelevant, at least in criminal trials. In a civil trial, it might be admissible, but ... then the discomfort (of the judges) starts to matter.
Good points! Thanks.
Delete1. Yes, I think the statistical machinery could generalize...do you have another behavior you think it would be interesting to apply it to? As I explain in the post (footnote 1), I don't find "herd mentality" super-plausible when it comes to people bringing sexual assault allegations.
2. The conclusions in the model are robust to whether we assume serial offenders are responsible for most assaults. I think this assumption is reasonably well-substantiated by Lisak's work, though (I'm not sure what contrary evidence you're alluding to -- if it's the recent JAMA serial assaulters paper, I wasn't persuaded that that actually contradicted Lisak's results.)
3. Yes, false allegations might come from people the accused has not had sex with. Evidence suggests that the rate of such false accusations is very low.
4. Yes. Perhaps we should change our court procedures?
I think the model would be just as useful for other crimes (or anti-social behavior in general). I think herding would be more likely for relatively minor or anonymous crimes, like shoplifting. ("Oh, that weird guy who made me uncomfortable was just accused of shoplifting down the street. Maybe I should see if anything is missing and report him." [implicitly assuming that the missing stuff was lifted by him in particular]) I do agree that the anonymity box largely deals with this problem for sexual assault in particular.
DeleteI won't argue about what proportion of assaults are made by serial offenders -- I have seen suggestive but not overwhelming evidence both ways. When you say that the model is robust against this, do you just mean that it won't catch as many perpetrators, but the ones it does catch are still overwhelmingly likely to be flagged correctly?
I agree that naming-the-wrong-perpetrator is less of a problem for sex assault in particular, barring conspiracy or lots of media attention. I do worry that eyewitness testimony is quite poor compared to the confidence we give it, and once a particular stranger has been identified (even wrongly) as a suspect, he will attract more than his share of accusations. In fairness, that isn't a problem for identifying suspects; only for deciding to prosecute.
http://fivethirtyeight.com/features/a-data-detective-story-did-a-british-nurse-kill-his-patients/ may be relevant when considering how (or whether) courts will (or should) consider statistical evidence.
DeleteThis comment has been removed by the author.
ReplyDeleteI have a few objections, but seeing as this is an old blog post, I would just like to confirm that you still read new comments on this page before I write a detailed response. If you are reading this comment, can you please reply so I know you're still here?
ReplyDeletehi andrew! sure, fire away.
Delete1) Where do you draw the line between what is and isn't consent? I am of the opinion that any sex in which both parties give verbal consent and remain active and willing participants (ruling out unconscious or coerced sex) for the entirety of the intercourse should be considered consensual. Whether or not the parties were intoxicated shouldn't matter because chosing to consume alcohol does not mean you are no longer responsible for your actions, and being an active and willing participant in a sexual encounter is a conscious choice. For some reason this opinion is controversial, particularly on college campuses, and in the past few years we have seen incidents at Occidental, Vassar, and Amherst where a student gets expelled (and their record tarnished) in spite of on overwhelming body of evidence that the sex was in fact consensual. The Amherst case is particularly troubling as the accuser was not only the instigator of the encounter, but the accused student was not even conscious for the entirety of the intercourse. Slate has a really good article on this subject that I highly recommend reading:
Deletehttp://www.slate.com/articles/double_x/doublex/2015/02/drunk_sex_on_campus_universities_are_struggling_to_determine_when_intoxicated.html
2) Human memory is not very reliable. Humans frequently reinterpret their memories based on experiences they had after the event occurred. This is why eyewitness evidence is considered by legal experts to be the least-reliable for of evidence, and why witness contamination is such a major problem for criminal investigators. One famous example of this phenomenon is the crash of TWA flight 800, in which there one witness told the media they thought the plane was shot down by a missile. This was widely reported and caused other witnesses to reinterpret their memory of events and also claim it was a missile. The result was a situation in which hundreds of witnesses would swear on their life that they saw a missile, despite all of the physical evidence indicating that the plane was brought down by a fuel tank explosion. This same problem exists with sexual assault, especially on college campuses where drunken, forgetful sex is common and ideologically driven teachers and student advisors are always on the lookout for anything that could possibly be viewed a rape. There have been instances where a student who had drunken sex the previous night would swear that she was not raped, but a student student advisor demands she see a rape counselor, and after a couple hours of talking to the counselor her whole recollection of events is altered. This is a very informative lecture regarding how the shortcomings of human memory often muddy the waters around sexual assault:
Deletehttps://www.youtube.com/watch?v=TGMi0UtvTIc
I don't think your statistical analysis controlled for these scenarios, so I just wanted to bring them to your attention.
DeleteAdditional information regarding Amherst sex scandal:
http://reason.com/blog/2015/06/11/amherst-student-was-expelled-for-rape-bu
https://www.theatlantic.com/education/archive/2017/09/the-uncomfortable-truth-about-campus-rape-policy/538974/
Additional information regarding the false memory phenomenon:
http://www.slate.com/articles/health_and_science/the_memory_doctor/2010/05/leading_the_witness.html
https://en.wikipedia.org/wiki/Eyewitness_memory
https://en.wikipedia.org/wiki/Memory_conformity
Hi!
ReplyDeleteThanks for all these links. I’m aware of both these points, as they’re fairly frequently made and I’ve worked for a while on these questions; see my pieces in the NYT or Washington Post for examples. While the statistical model abstracts away the details of assault, it does deal with the points you make. Each of these phenomena either a) lower the baseline probability that assault in fact occurred (in which case multiple accusations still increase the posterior probability) or b) create correlations between accusations (a point dealt with in point 1 above).
I’ll note incidentally that I don’t think people who are blackout drunk can consent to sex. I think this is pretty obvious if you’ve ever dealt with someone who is blackout drunk. Adopting such a standard also creates a huge perverse incentive to get people blackout drunk so they’ll make bad decisions without fear of consequences. And it’s inconsistent with how we deal with other cases, like gambling: for example, “Nevada law prohibits permitting visibly drunk patrons to gamble, as well as serving them the aforementioned free drinks if the patron appears to already be bombed”. In general, it seems like a very bad idea to allow people to get people drunk and exploit them and claim they consented.
The reason we claim you’re still morally responsible if you _hurt other people_ while drunk is that not doing so would create a perverse incentive: get drunk and hurt whoever you want.
I’m curious — how likely do you think it is that all the high profile men currently being accused of assault are innocent?
I just wrote a long and thoughtful reply to your comment and then lost the whole thing because I accidently refreshed the page, so I will keep this brief and elaborate further later on (it's 3 am and I'm tired).
ReplyDeleteBasically, I feel like "active and willing participant" would discount someone on the brink of consciousness because they would be physically incapable of meeting that criterion. Also, I feel like your reasoning stems from an assumption that sex is something that a man "does to" a woman, in which he is the actor and she is merely being acted upon. I don't see it that way, but rather as a voluntary exchange between two mutually interested parties who each possess equal agency and is responsible for his or her own actions. These are adults we're talking about, so I think the paternalistic approach is the wrong way to go.
As for your question, I find it highly unlikely that they are *all* innocent, but I think there's a reasonable chance that at least *one* is. Therefore I believe it is imperative that we proceed with caution and carefully weigh the available evidence in each individual case. We must resist the temptation to rush to judgement just because we have a bunch of similar cases all surfacing around the same time, because the next one we examine may very well be the one in which the accused is truly innocent. As William Blackstone famously said, "It is better that ten guilty persons escape than that one innocent suffer"